




Multi-Bucket Performance Tier Scale Out Backup Repositories in Veeam VBR v12 Beta 3
Screenshot of Veeam 12 beta
As we come upon the end of the year, we are also getting closer and closer to Veeam’s latest release of their flagship product, Veeam Backup & Replication v12. Here at 11:11 Systems we have been testing quite a bit with the beta code as it has been released because there are quite a few features to really be excited about here. For me personally the biggest is being able to use object storage as a first hit repository and to be able to scale them out.
If you are not yet familiar with object storage now is the time. Object storage provides a good deal of native capabilities we’ve never had when using block-based storage (like volumes and partitions). These include:
- Immutability
- Versioning
- Consumption based pricing model
What this means to your backup plans is that you will have more capabilities, while being more agile in pricing.
Flavors of Object Storage
11:11 Systems Object Storage screenshot
There are several ways to purchase and consume object storage. The hyperscale cloud names you are probably most familiar with: Amazon’s AWS (Amazon Web Services) S3 and Microsoft’s Azure Blob. But these providers can have several potentially unexpected costs around data egress, API call limits, and in some cases how long you store the data. As we all know with IT and disaster recovery, a good deal of our decisions come down to cost and budgeting, so having unexpected bursts can be a challenge.
With 11:11 Object Storage, you get access to a robust, performant object storage service that while competitively priced is flat rated with nothing hidden. Our service and others that use the AWS S3 API structure are commonly called S3 compatible. This means that they support the same calls and automation capabilities as S3 but may have differing architecture.
Finally, there are also a few physical device manufacturers such as Pure Storage, Cloudian and Object First that will sell you arrays for on-premises object storage. With the 3-2-1 backup model it may be worth considering an on-prem option for your first hit of backups before copying to the cloud.
Optimizing for Performance
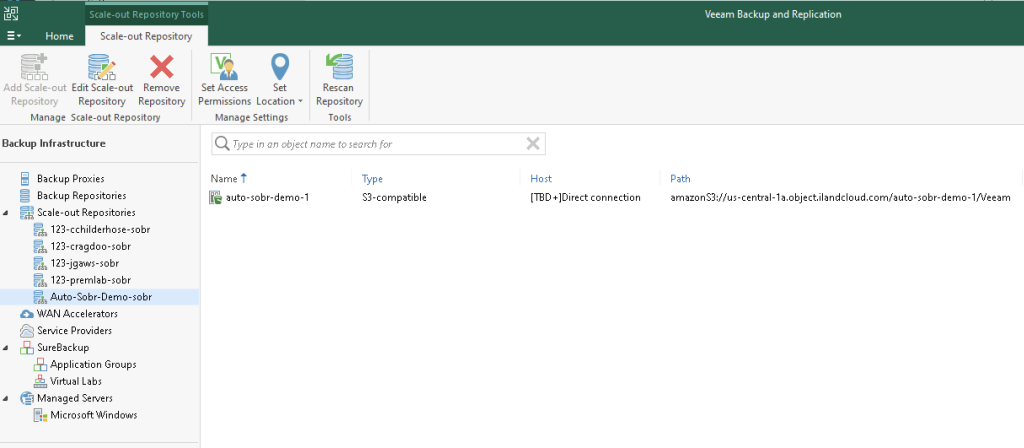
One consideration as we begin to look at object storage for backup data is that depending on the platform the service is built on, there may be performance considerations as buckets scale in number of objects. In previous versions of VBR only a single bucket was supported for the capacity or archive tier. In this latest version, multiple buckets will be supported per tier, a move that is anticipated to enhance performance. At 11:11 Systems, we have put a great deal of work into overcoming limitations both in object storage itself but also how Veeam software integrates with it to the point that we consider it as performant if not more so than most other offerings in this space. This includes taking an active role in the open source Ceph project that powers our service.
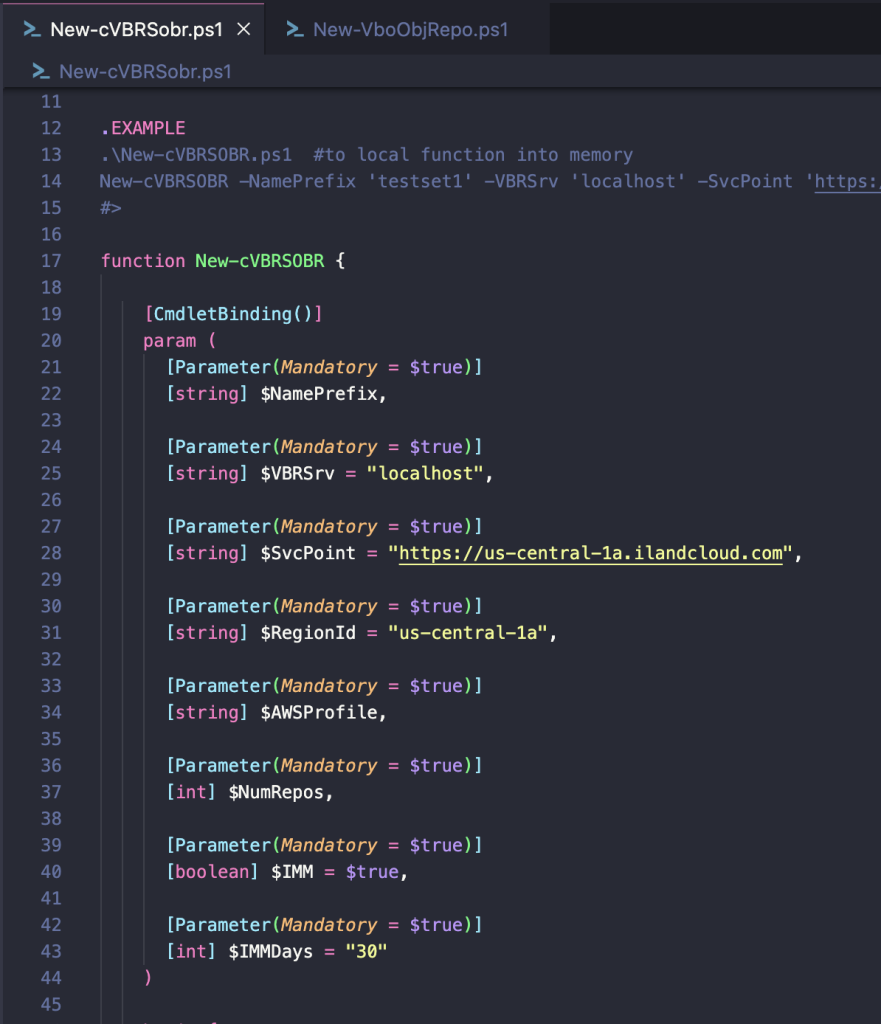
As I began working on testing this capability, I realized that I was spending a lot of time creating buckets, creating repositories, and then ultimately creating SOBRs full of repositories. In speaking with my friend Joe Houghes we realized we were both doing the same things and so we collaborated on scripting this capability, the final product of which can be found in this GitHub repository. If you do choose to use this, please provide feedback through GitHub.
While the code is great, the takeaway you should consider here is that Object Storage as the repository portion of your VBR Infrastructure is coming. With that great capability comes great consideration and you should look to work with experts to assist you with these changes. You should also begin to educate yourself on the key capabilities and differences.





